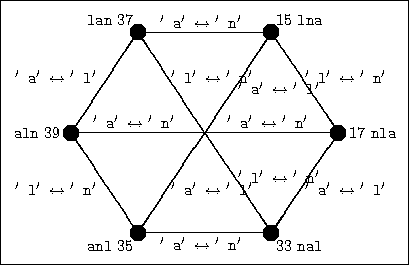
Figure 30 summarizes the distances of bigram tables for each key for
Figure 29, reorganized as follows. The corners of the
``hexagon'' indicate each key with its corresponding bigram distance
nearby. Two keys/corners are connected with a line if each key is
obtainable from the other key by swapping two letters.
Rather than inspecting each key, here is a modifed approach. Consider trying to reach the best key "lna" from the starting key "aln" by traveling along a ``path'' in Figure 30. One ``path'' is from "aln" to "nla" to "lna", which has the property that from each key we go to its best ``neighboring'' key:
| Roadmap | |
| Section 3.7 | Encipher plaintext
|
| Section 3.7 | Decipher ciphertext
|
| Section 4.2 | (Hope)
Unscramble frequencies
|
| Section 4.3 | Unscramble = Bring ``close'' to intrinsic frequencies |
| Approximate intrinsic frequencies with training text | |
| Assume ciphertext is medium to large so that unscrambled frequencies resemble intrinsic frequencies | |
| Section 4.4 | Use the L1 distance to measure ``closeness''; ignore labels. |
| Section 5.1 | Sorting unigram frequencies does not work, but ``almost'' does. |
| (Hope) When the frequency table for ciphertext matches the table for training text, read the encryption key off of the labels | |
| Section 5.2 | ``Sort bigram frequencies'' is problematic. |
| Section 5.3 | Exhaustive search is too slow; therefore, need an incomplete search. |
| Section 6.2 | Q: How do we perform an effective, incomplete search? |
| Section 6.1 | (Idea) Hill-Climbing: pick the best ``neighbor'' |
|
|
Why swaps are so important, e.g. used to generate ``neighbors'' |