Our goal can be formulated as follows: Find a decryption key that when applied to ciphertext unscrambles bigram frequencies. This is a search, and one fundamental search algorithm is to try all possibilities:
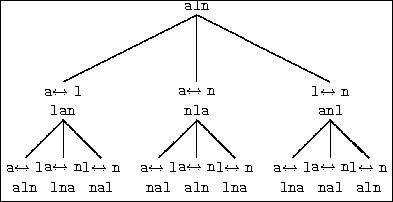
For instance, suppose you have a three element character set 'a',
'l', 'n'. Figure 28 shows all possible decryption
keys for this character set -- only the bottom lines are shown and
a
![]() n means ``swap 'a' with 'n'''.
n means ``swap 'a' with 'n'''.
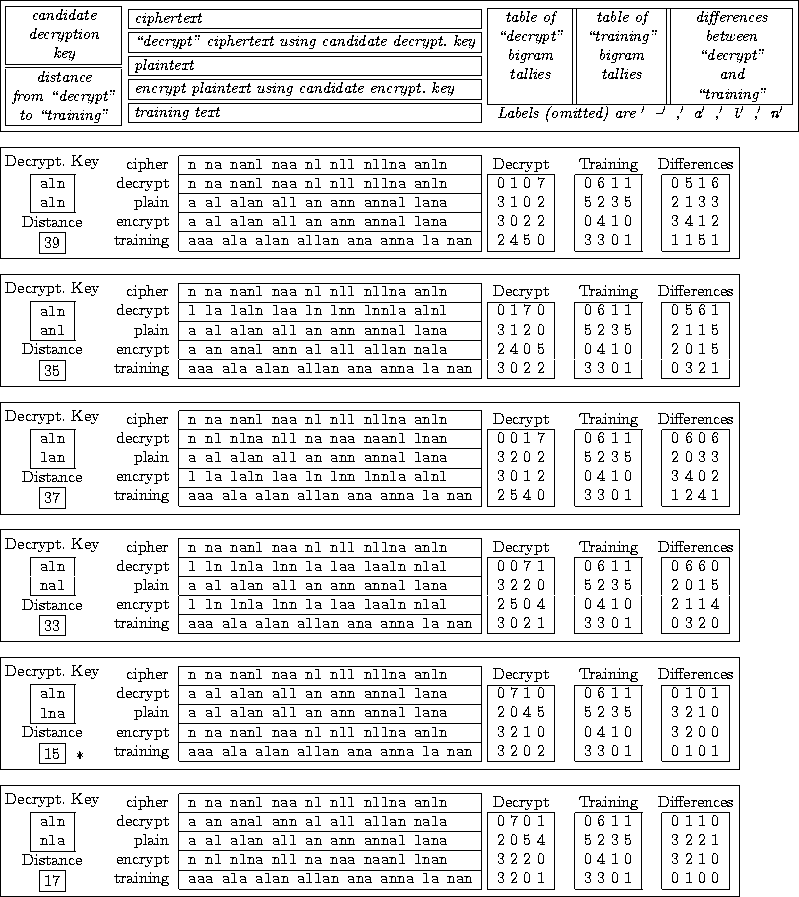
Suppose you need to decrypt a ciphertext that uses this three-letter character set and a '-' for spaces. Apply all candidate decryption keys from Figure 28 to the ciphertext.8 Each time you apply a different key to the ciphertext, you generate something you hope is plaintext. Collect the frequencies from the hoped-for-plaintext. Choose as the decryption key and the plaintext the key and text with frequencies closest to intrinsic frequencies.9 Figure 29 shows this exhaustive search, and note that indeed the minimum distance 15 corresponds to the decrypted ciphertext.
For ``small'' alphabets, we can reasonably perform an exhaustive
search. However, what if the language has a relatively ``large''
character set? Consider English, which has 26 letters, not counting
punctuation. There are
![]() decryption keys for
a 26-letter alphabet! Machines these days cannot perform more than
about a billion (109) operations per second, so even if they could
look at a billion ciphers per second, it would still take
decryption keys for
a 26-letter alphabet! Machines these days cannot perform more than
about a billion (109) operations per second, so even if they could
look at a billion ciphers per second, it would still take
![]() seconds, or over 1010 years! So, you will
have to find a better approach to crack EGOP's message since you have
until May 4, 2000!
seconds, or over 1010 years! So, you will
have to find a better approach to crack EGOP's message since you have
until May 4, 2000!
Therefore, we must use an incomplete search that looks at only a (small) subset of the keys. We answer the questions ``Which keys?'' and ``How do you pick them?'' in the next section.
| Roadmap | |
| Section 3.7 | Encipher plaintext
|
| Section 3.7 | Decipher ciphertext
|
| Section 4.2 | (Hope)
Unscramble frequencies
|
| Section 4.3 | Unscramble = Bring ``close'' to intrinsic frequencies |
| Approximate intrinsic frequencies with training text | |
| Assume ciphertext is medium to large so that unscrambled frequencies resemble intrinsic frequencies | |
| Section 4.4 | Use the L1 distance to measure ``closeness''; ignore labels. |
| Section 5.1 | Sorting unigram frequencies does not work, but ``almost'' does. |
| (Hope) When the frequency table for ciphertext matches the table for training text, read the encryption key off of the labels | |
| Section 5.2 | ``Sort bigram frequencies'' is problematic. |
| Section 5.3 | Exhaustive search is too slow; therefore, need an incomplete search. |
|
|
Q: How do we perform an effective, incomplete search? |