In this handout, we provide static semantics for the Iota+ programming language, as a modification to the earlier Iota static semantics.
Representing types in Iota+ is quite a bit trickier than in Iota, because of several interacting features. Iota+ supports object types (interface and class types). Interfaces may introduce new object types and they may be imported into other modules. These types may be recursive: they may refer to themselves. A collection of types declared in the same interface may be mutually recursive, in fact. To keep our typing rules as simple as possible, we represent object types in a simple way that corresponds directly to a reasonable implementation of a type checker.
In these rules, there are two notions of type. There are the type expressions that appear in the source language, which are described by the following syntax from the language definition:
type ::= id | object |
int | string |
bool | array [ type
]
There are also the types T that appear in typing judgments A ` E : T. (The rules for constructing legal types T are given below). The typing rules are clearer if we draw a distinction between these two notions of type. In the Iota typing rules, this distinction was already suggested by the use of bold face when writing types in judgments and the use of a fixed-width code font when writing type expressions that appear in programs. We can think of types written in bold face as standing for pointers to type objects manipulated by the compiler, whereas types written in code font stand for the corresponding abstract syntax tree.
An issue that was implicit in the Iota rules is how to interpret type expressions as types. Interpretation becomes interesting with the introduction of class and interface types, because these types must be looked up in the current environment when encountered to determine whether they are valid types. An identifier N, used in a position where a type is expected, should not simply be converted to an internal representation as a type object; it must be validated in the current environment. We will write the judgement ` t ) T to indicate that the type expression t is well-formed, and that it represents the type T. (In simple languages like the ones that you would encounter in a typical programming-languages class (e.g., CS 411/611), the issue of type interpretation doesn't arise because interpretation is trivial.)
In our rules, we will represent the type of a class C as Nm.C, where Nm is the name of the current module. Similarly, an interface type I defined in the current module will be written as Nm.C. An interface type I defined in another module named N will be represented by N.I. As indicated above, the implementation of a qualified identifier N.X may simply be a pointer to the corresponding type object. (We will write X when it may be the name of either a class or an interface.) Formally, the actual information about the method signatures for these types is stored in a global environment that we will name G. We write G[N.I] to denote an environment that maps method identifiers to their corresponding type signatures; similarly, G[N.C] maps method and field identifiers to their types. Although an expression like G[N.X] suggests that we look in a symbol table G to find the environment for the components of the type, a better way to implement G[N.X] is as an invocation of a method of the type object N.X, where that method returns the environment that describes N.X. To keep typing judgments concise, the global environment G doesn't appear explicitly although it is always present along with the ordinary typing context A.
The rules for interpreting types and constructing the global environment are given later.
In addition to the standard typing judgment present in Iota, A ` E : T, there is a new judgment about subtype relationships, `T1 <: T2. The first judgment says that the expression or statement E has the type T. The second judgment says that T1 is a subtype of T2. There are certain axioms that extend the power of these judgments. First of all, there is the fundamental subsumption rule that connects these two kinds of judgments:
| A `
E : T1 `T1 <: T2 |
| A ` E : T2 |
In addition, the subtyping relation is reflexive and transitive, so it is a preorder:
`T1 <: T2 |
||
`T <: T |
`T1 <: T3 |
The types unit has associated subtyping
axioms: for all types T, T <: unit. Also, the types Null and object
have predefined subtype relations: for all class and interface types M.X,
M.X <: object and Null <:
M.X. Also, the types string and
array[T] are subtypes of object and supertypes of Null.
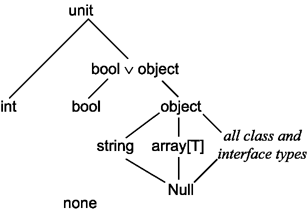
A Hasse diagram of these and other subtyping
relations is given below. Note that the types Null and none are
quite different, despite the similarity of their names. The type Null has
a single value, the constant null. The type none has no
values because it is the type of expressions that do not even return control to
their evaluation context.
Finally, we have a rule for inferring subtype relations among different object
types. This rule assumes that the global environment G contains a set of
subtype declarations, in addition to the interface and class environments
described earlier. As described below, these subtype declarations are installed into G as extends
and implements clauses are processed (and the signatures of the
types allegedly related by these clauses are checked for subtype conformance).
| T1<:T2 2 G |
|
`T1 <: T2 |
Note that more indirect relationships in the subtype hierarchy are derived from the rule for transitivity.
The hierarchy of types induced by the subtype relation is conveniently summarized by the following diagram:
Note that several of these types cannot be mentioned directly in an Iota+ program: unit, none, Null, and bool _ object. Unlike in Java, there is no subtype relation between two types array[T1] and array[T2] unless T1=T2.
The rules for existing Iota expressions remain the same, although they become richer because of the addition of the subsumption rule. However, various new expressions have been added to the language and rules for checking them are needed.
The type of the new expression this is looked up in the environment under the
special name this:
| this:T 2 A |
|
|
A `
this : T |
The type of the new expression null is always Null:
for all environments A, A `
null : Null.
The type of the expression new C, where C is the
name of a class type, is the class type Nm.C; it requires a check that the class
actually exists:
| G[Nm.C] = Ac |
A ` new
C : Nm.C |
The type of a field access is looked up in its class environment (id denotes an identifier):
| A ` E : N.C |
| G[N.C] ` id : T |
| A ` E . id : T |
A method call is checked by ensuring that the types of each of the actual expressions supplied as arguments are the same as the declared types of the formal arguments. Note that this rule looks in the appropriate class environment to find the signature of the function named id.
| A ` E :
N.X ( id: T1 æ T2 æ ... æ Tn!T ) 2 G[N.X] A ` Ei : Ti i21..n |
A ` E . id ( E1,...,En ) : T |
Finally, the cast expression has exactly the type it claims to (the
expression returns null if necessary to make this happen):
| A `
E : TÇ ` t ) T `TÇ <: object `T <: TÇ |
A `
cast ( E, t ) :
T |
Some existing Iota expressions are changed slightly. The &, |,
and ! operators accept object types as arguments as well as booleans:
| A ` E1 : bool
_ object A ` E2 : bool _ object |
A ` E1 : bool
_ object A ` E2 : bool _ object |
A ` E : bool _ object | ||
A ` E1 &
E2 : bool |
A ` E1 |
E2 : bool |
A ` !E : bool |
The union type bool _ object sits above both bool and object in the type hierarchy: bool <: bool _ object and object <: bool _ object. The subsumption rule will automatically shift the type of an expression up to bool _ object when necessary. The operators that can accept either a boolean or an object are then typed as accepting values of type bool _ object. However, we are prevented by the type system from assigning an object directly into a boolean variable, which will help avoid the programming errors that can occur in C (which allows such assignments).
For == and !=, two values may be compared as
long as they have a common type that is not unit,
none, or
bool _ object.
| A `
E1 :
T A ` E2 : T T is not unit, none or bool _ object |
A `
E1
== E2 : bool |
The rule for != is identical to the rule for ==,
and the rules for <= and >=
are the same as for < and > in Iota, but are extended
to allow comparisons of bool as well as int
and string.
Statement forms also are extended in Iota+. The subtype relation between unit, none and other types in the type system actually makes it easier to express rules about statements.
There is a new kind of assignment statement: an assignment to a field. We will treat assignment statements as if they were expressions for the purpose of type checking. This treatment allows multiple assignment to be checked conveniently without changing the previously existing rules for checking assignment, recalling that assignment associates to the right.
| A ` E1 : Nm.C | this: Nm.C 2 A | |
| id: T 2 A[Nm.C] | id : T 2 A[Nm.C] | |
| A ` E2 : T | A ` E2 : T | |
| A ` E1 . id = E2 : T | A ` id = E2 : T |
The new increment and decrement can be type-checked (though not translated!) exactly as if they were assignments to an addition expression:
A ` E =
E + 1
: int |
A ` E =
E - 1
: int |
|
A ` E++
: int |
A ` E--
: int |
The if statement and while statement are augmented to allow their test expressions to be either of type bool or of type object. Because of the subsumption rule and because unit is a (nearly) universal supertype, a special rule is no longer needed for the case where the two arms return different types:
| A ` E : bool _
object A ` S : T |
A ` E : bool _
object A ` S1 : T A ` S2 : T |
|
A ` if (
E ) S :
unit |
A ` if (
E ) S1 else S2
: T |
Finally, we have rules for the case of an if statement
whose arms have type none, allowing one or both arms not to terminate
normally:
| A ` E : bool _
object A ` S1 : T A ` S2 : none |
A ` E : bool _
object A ` S1 : none A ` S2 : T |
|
A ` if (
E ) S1 else S2
: T |
A ` if (
E ) S1 else S2
: T |
A while statement always has the type unit, and requires
that its test expression has type bool or object. In
addition, a special entry is added to the environment under the keyword break.
When a break statement is encountered, this entry is checked for. If the
entry is not present, the break statement has occurred outside any containing
while statement and is therefore illegal. The type of a break statement is
none because, like a return statement, the statement does not transfer control to the containing context.
| A ` E : bool _
object A, break ` S : T |
A ` S : T | break 2 A | ||
A ` while (
E ) S : unit |
A ` while (true)
S : none |
A ` break
: none |
Note that a statement of the form while (true) S is given the
type none, but only if S does not execute any break
statements that would cause the while loop to terminate normally. This is
enforced in the rules by having two rules for type-checking of S; in practice, we want to try the none rule first since it subsumes the unit rule
when it is applicable.
A return statement is checked as
before, except that it is given the type none in Iota+:
| return: unit 2 A | A ` E :
T return: T 2 A T is not unit |
|
IA ` return :
none |
A ` return
E : none |
Finally, the rules for checking blocks of statements (block, decl block) are changed to prevent a statement with type none from making the subsequent statements unreachable, and to allow multiple variables to be introduced at once:
|
A ` S1
:
T1 S1 is not a declaration T1 is not none A ` ( S2 ; ... ; Sn ) : Tn
|
A ` S1
:
T1 S1 = id1,...,idm : t [ = E ] T1 is not none ` t ) T A, id1:T,...,idm:T ` ( S2 ;...; Sn ) : Tn
|
|
|
|
|
|
A ` ( S1
; ... ; Sn ) : Tn |
A ` ( S1
; ... ; Sn ) :
Tn |
Declarations contain some type expressions that must be interpreted:
| ` t ) T | A ` E :
T ` t ) T |
||
|
|
(decl) |
|
(decl init) |
| A `id: t : unit | A ` id : t = E : T |
The rules for checking functions and methods are the same; the only
difference is whether the pseudo-variable this is in scope. The only change to the
Iota rules is explicit interpretation of the argument and result types:
|
A, a1 : T1, ..., an : Tn, return : Tr ` E : Tr |
|
| `ti ) Ti i2{r}[1..n | |
|
|
(fcn defn) |
|
A ` id(a1 :
t1, ..., an : tn) :
tr = E
defn |
|
A, a1 : T1, ..., an : Tn, return : unit ` E : Tr |
|
`ti ) Ti
i21..n |
|
|
|
(proc defn) |
|
A ` id(a1 : t1, ..., an : tn) = E defn |
To make Java and C programmers feel more comfortable with Iota+, the body of
a function definition may have type none. This permits the body to be a
sequence of statements ending in a return statement. It also permits a function
body to end in while(true) loop. The corresponding new rules are
the following:
|
A, a1 : T1, ..., an : Tn, return : Tr ` E : none |
|
| `ti ) Ti i2{r}[1..n | |
|
|
(fcn defn none) |
|
A ` id(a1 : T1, ..., an : Tn) : Tr = E defn |
|
|
|
`ti ) Ti
i21..n |
|
|
|
(proc defn none) |
|
A ` id(a1 : T1, ..., an : Tn) = E defn |
As in Iota, the goal of the type checker is to determine whether an entire module M is well-typed. It tries to derive the judgment ` M : I module, where M is the text of the module. In Iota, two passes were needed over the module: one to pick up the signatures of all the functions, and a second to actually check the function bodies. The first pass was performed by the function module-ctxt. There are two new problems that we run into in Iota+. First, module processing must be extended to handle the new kinds of definitions found in Iota+, including interface type declarations, class definitions, and constant definitions. The second problem is that signatures of functions and methods appearing in the module may be uninterpretable on the first pass, because the compiler will not necessarily know all of the types it needs to in order to understand the field and method signatures of the class. There are three ways of dealing with this problem, as described in lecture. One approach is to enter the class and interface type definitions into the symbol tables using un-interpreted type expressions (AST nodes). This approach requires that the appropriate environment always be carried around to resolve identifiers used in the AST trees that represents types. A second approach is to add a pass over the symbol table that interprets all of the type expressions used in the class member signatures and replaces the symbol table entries with fully-resolved entries. The third approach is to add an initial pass over the module to acquire all the legal type names, before trying to interpret any type signatures. It is this third approach that corresponds most closely to the semantics given here, but you may choose to implement type-checking in a different way if you find it more convenient.
In addition, new rules must be added to check the new kinds of module definitions. Other than these additions, modules can be checked in the same way as before. As in Iota, a module must implement all of the values declared by its interface: module variables and functions. There is no need for a module to provide an implementation for interface types or for constant declarations, since the module interface already states everything that one can know about these module components. When a module implements a component that is declared in its interface, the type of the component must conform to that declared in the interface. For variables, the two types must be equal. For functions, the type declared in the module must be a subtype of that declared in the interface. In other words, the types of arguments used in the actual definition of the function may be supertypes of those declared in the module interface, and the return type may be a subtype.
Class and interface definitions must also follow certain rules in order to avoid name clashes and type errors. A class or interface type may not define any member that has the same name as any supertype member, unless the member is a method and its signature conforms to that in the supertype in the required contravariant/covariant manner. No class member may have the same name as any function, top-level variable, class or interface in the module, either, because otherwise there would be ambiguity about what that member meant within the body of the methods of the class. Interface members may have the same names as global identifiers because they are never introduced into scope automatically.
The first pass over the source generates a set of identifiers representing types that may be legally mentioned in the module. For each such identifier, the corresponding qualified identifier N.X and the kind of the type are recorded. The module name N is the module in which the identifier is actually declared, even if that identifier is imported through a chain of interfaces. In Iota+, a user-defined identifier may denote only two kinds of types: class types and interface types. This initial context is called a kinding context because it keeps track of the kinds of type-denoting identifiers (rather than the types of value-denoting identifiers). The kinding context is used to check that type expressions are well-formed, just as the typing context is used to check that terms are well-formed. We define a function kind-ctxt(N ; I ; M) that constructs a kinding context for the module whose name is N, whose interface is I and whose text is M. The kinding context is a set of bindings x :: K where x is an identifier and each identifier is bound at most once. For Iota+, a legal kind K has the form class N.C or interface N.I. Here, x is the identifier by which the type is known in the current module, N is the defining module, and C or I is the name used to define the type in its home module. For identifiers that do not denote types, a binding of the form x :: value is added to the kinding context; because well-formed contexts contain no duplicate bindings, these entries allow detection of identifier clashes.
kind-ctxt(N ; uses U1,...,Un
D1,... Dm ; ) =
uses-kind(U1), ..., uses-kind(Un) , decl-kind(N,
D1),
..., decl-kind(N, Dm)
kind-ctxt(N ; I ; uses U1,...,Un
D1,...Dm ) =
kind-ctxt(N ; I ; ), uses-kind(U1),
..., uses-kind(Un), defn-kind(N,
D1),
..., defn-kind(N, Dm)
The function uses-kind extracts a kind binding from a
uses item. It is conveniently defined using inference rules:
x:: K 2 kind-ctxt(N ; parse(N.ii)
; )
|
x2 :: K 2
kind-ctxt(N ; parse(N.ii) ; )
|
|
| uses-kind(N.x) = x :: K | uses-kind(x1 = N.x2) = x1 :: K |
The functions decl-kind and defn-kind do the same job for declarations and definitions, respectively. Only defn-kind is given; decl-kind is very similar.
defn-kind(N, class C { D1...Dn
}) = C :: class N.C
defn-kind(N, interface I { D1...Dn
}) = I :: interface N.I
defn-kind(N, x : T [ = E]) = defn-kind(N,
x(...)
[ : T ] = E) = defn-kind(x = E)
= x :: value
Type well-formedness and interpretation rules. Let us denote a kinding context with K. Using this context,
we can now express the rules for type interpretation. First, there are a number of
obvious axioms: K`int)int,
K`bool)bool,
K`string)string,
K`object)object.
In the typing rules earlier, we left the context implicit, but in general we
need to interpret types in different contexts. The more interesting rules concern array
types and user-defined object types. As these rules show,
we can distinguish between class and interface types, which is important for
some of the ordinary typing rules.
| K`t)T | C:: class N.C' 2 K | I:: interface N.I' 2 K | ||
|
|
|
|
||
K`array[t])array[T] |
K`C)N.C' | K`I)N.I' |
Note: If we were pedantic about writing the typing rules, we would need to include the global context G and the kinding context K in all the typing rules given earlier. The full static context for typing an expression is a triple K;G;A, the typing judgement has the form K;G;A ` E :T, the subtyping judgement has the form G`T1<:T2, and the type interpretation judgment has the form K ` t)T as we have just seen. To keep things simple, these details have been largely elided. However, they will have some manifestation in any correct implementation of type-checking.
The next phase of our formal semantics defines the global context G that binds qualified identifiers to their definitions and also records any declared subtype relations. In the implementation, this formal definition might correspond to filling in type objects created as placeholders in the previous pass. Other work can be carried out at the same time: type signatures can be acquired for module functions and variables. The function global-ctxt(K ; I ; M ) generates the appropriate global environment. The global context is a set of subtype declarations T<:TÇ and qualified identifier–environment bindings N.X := A. Because a given definition may result in multiple entries in the global context, we need a way to merge together two global contexts. We denote this merging with the symbol +; for example, G1 + G2. If the global context contains a binding N.X := A, then the notation G[N.X] denotes A.
global-ctxt(K ; ; ) = Ä
global-ctxt(K ; uses U1,...,
Un D1,...,
Dm ; ) =
global-use(U1) +...+ global-use(Un) +
global-defn(K; D1) +...+ global-defn(K;
Dm)
global-ctxt(K ; I ; uses U1,...,
Un D1,...,
Dm) =
global-ctxt(K ; I ; ) + global-use(U1) +...+ global-use(Un) +
global-defn(K; D1) +...+ global-defn(K;
Dm)
global-defn(K ; class C implements
I { D1...Dn }) =
Nm.C <: NÇ.IÇ, Nm.C
:= { defn-type(K ; D1) ... defn-type(K ;
Dn) }
where C :: class Nm.C
2 K, I :: interface
NÇ.IÇ
2 K
global-defn(K ; class C { D1...Dn }) =
Nm.C <: object, Nm.C
:= { defn-type(K ; D1) ... defn-type(K ;
Dn) }
where C :: class Nm.C
2 K
global-defn(K ; interface I1 extends
I2 { D1...Dn }) =
NÇ1.IÇ1 <: NÇ2.IÇ2,
NÇ1.IÇ1 := { defn-type(K ;
D1), ...,
defn-type(K ;
Dn) }
where I1:: interface
NÇ1.IÇ1 2 K,
I2:: interface NÇ2.IÇ22 K
global-defn(K ; interface I { D1...Dn }) =
NÇ.IÇ <: object, NÇ.IÇ := { defn-type(K ; D1), ..., defn-type(K ;
Dn) }
where I :: interface
NÇ.IÇ 2 K
global-defn(K ; D) = Ä (for all
other definitions D)
defn-type(K ; x : t [= E]) = x :
T
where K ` t
) T
defn-type(K ; x(x1:t1,
..., xn: tn) : tr = E)
= x : T1æ...æTn!Tr
where K `ti)Ti,
for i21..n, and K `tr)Tr
All type definitions in imported interfaces (including indirectly imported
interfaces) are entered into the global context G, whether or not they
appear in the kinding context K. This rule makes types available for
type-checking, even if they have not been imported into the module being checked
and hence cannot be named there.
global-use([x = ] N.xÇ) = global-ctxt(kind-ctxt(N ; parse(N.ii) ; ); parse(N.ii) ; )Note that types in the imported interface N are interpreted with respect to N's namespace kind-ctxt(N ; parse(N.ii) ; ) and not that of the module.
As in Iota, the function module-ctxt(I ; M) generates the module typing context. It must be extended to process the uses clause in the module's interface, if any, and to create entries for constant definitions in the interface and in the module. This extension has been left to the reader. Because module-ctxt does not depend on the G context, it can be computed at the same time, in the second pass.
The final pass is ordinary type-checking of module definitions, which proceeds mostly as in Iota. There are three new kinds of definitions to consider, however: constant definitions, interface definitions, and class definitions. Constant definitions are well-formed if their syntax is correct. Interface and class definitions require more checking.
Interface type definitions. An interface type declaration is legal if it does not extend anything or if the signatures of all of its methods are conformant with those in its supertypes, if any:
| `I )T
`I'
)T' G[ T ] ={ x1: T1, ... xn: Tn } conformant( xi, Ti, T' ) i21..n |
A ` interface
I extends I' { ... } defn |
A method is conformant either if no method of that name exists in any supertype, or if a method of that name exists, but with the same number of arguments, where the arguments in the supertype method are subtypes of the arguments in the subtype method, and the return type in the supertype method is a supertype of the return type in the subtype method. We can define the predicate conformant with three inference rules:
|
G[ T ] ={ x1: T1,
... xn: Tn } |
G[ T ] ={ x1: T1,
... xn: Tn } x =6 xi i 21..n T <: object 2 G |
|
| conformant(x, Tx, T) |
conformant(x, Tx, T ) |
| G[ T ] ={ x1: T1,
... xn: Tn } `Tx <: Ti |
| conformant(xi, Tx, T ) |
Class definitions. As for an interface; the method signatures of a class must be checked for conformance. However, a class definition requires three additional kinds of checks: the members of the class may not conflict with anything in the environment, all supertype methods must be implemented by some method body, and the method bodies must be checked as well.
| ` C
) TC A, this: TC, x1: T1, ... xn: Tn ` Di defn i21..n `I )TI G[TC] ={ x1: T1, ... xn: Tn } conformant( xi, Ti, TI) i21..n |
A ` class
C [
implements I ] { D1, ...,
Dn } defn
|
Note that a method in a class is checked in the same way as a function is, except that the typing context contains a binding from this to the type of the current class, and bindings from each of the class member names to their types. Otherwise, the same rules can be used for type-checking methods as for type-checking functions.