Take input from a file, extract all the words, convert them to lowercase, count their frequency, and output them as tuples (frequency, word) sorted in descending order by the primary key (frequency), and sorted in descending order by secondary key (word). The input file is 170K.
The implementation uses an updated version of the Iota Collection Classes. A hand-written lexer tokenizes the input into words, in the process converting them to lowercase. A HashMap from strings to Counter objects is used to count the frequency of each word. A List is then constructed from the entry set of the HashMap. A custom Comparator that implements the above sorting rule is then used to sort the list with the new function Collection.sortList, which is implemented in the same way as the Java method Collection.sortList.
This tests all the object-oriented features of your compiler, particularly semantic analysis. It also tests the efficiency of your compiler's casting implementation.
Source: [WordFreq.im Collection.ii
Collection.im wordfreq.cpp
WordFreq.java]
Input: wordfreq.txt
Output: wordfreq.out
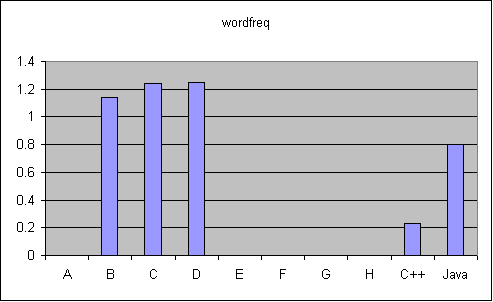
| C++ | 0.39 | |
| Java | 0.8 | |
| B | 1.14 | |
| C | 1.24 | |
| D | 1.25 |