Introduction
Goals, Resources and Procedures
The
first step of our investigation was to identify classes oferrors
typical of transfer based MT systems.We
submitted each of the four non-English texts to the two transfer-based
MT systems for translation into English.Comparing
the output of the MT systems with the original texts and with the native
English article, we generated a list of errors.From
this list, we developed an observational classification of the error types.In
the second phase of our investigation, we partitioned the error classes
into three broad categories:those
which will not be ameliorated by IL-based MT because they are caused by
lack of resources, those which will not be ameliorated because they involve
problems beyond the scope of MT, and those which will be ameliorated by
IL-based MT.Finally, we chose example
sentences from the source text, created IL representations of them loosely
based on Dorr?s Lexical Conceptual Structures (Dorr 1993), to demonstrate
how an IL representation could improve translation quality.These
examples will serve as a reference point for discussion during the present
IL workshop.
Classification of Errors
·remarks
concerning the classification of the error.
Classification of
the errors was based on all of the factors listed above, as well as the
authors? knowledge of the systems in question.The
result is the observational classification of errors below.We
do not claim that this is a complete classification of errors made by transfer-based
MT systems, that these errors are inherent to transfer-based systems, or
even that this is the correct classification.The
purpose of the classification is merely to separate those problems that
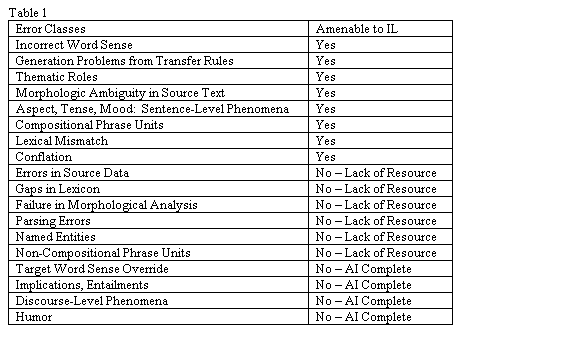
are amenable to an IL treatment from those that are not.Table
1 shows the categories of errors which will be described in the next section.
Where IL Will
Make a Difference
We have discovered
that eight of our classes will benefit from IL-based MT.We
regard these errors as inherent (though probably not unique) problems of
transfer-based MT.
1.Incorrect
Word Sense. Since an IL representation of a source language sentence is
intended to be unambiguous and meaning-preserving, cases involving problems
with word sense will benefit from an IL treatment.This
is a vast class, and includes issues such as polysemy, semantic content
of prepositions, and fine-grained sense distinctions.For
example, the French document contains the subheading ?Un succès
éclatant? (lit. ?a success bursting?), which was translated
as ?A Vivid Success?, ?A Bright Success?, and ?A Stunning Success? by Globalink,
Systran, and a human translator, respectively.None
of these is necessarily incorrect, but perhaps one captures the meaning
of the original more precisely than the others.As
a more mundane example the noun portefeuille has the multiple senses
?wallet? and ?portfolio?, both of which are potentially valid in a financial
domain.A clear (IL) meaning representation
of the source sentence will enable the generation of the correct form in
the target language.
2.Generation
Problems Attributable to Transfer Rules.Errors
such as French ?spécialisée dans la microfinance?
translating to ?specialized in the microfinance? seem to be the results
of specific transfer rules.In the
most extreme case, transfer-based systems default to substitution systems,
often resulting in so-called ?word salad?.
3.Thematic
Roles.A verb has a set of argument
structures or thematic grids in which it may appear.Arguments
are associated with these thematic roles, and this association is reflected
in the content of IL representations.This
will help avoid mistranslations such as Spanish ?brinda? asistencia técnica
a? to English ?offers to technical attendance to??.Aside
from the word sense problem (asistencia should be assistance
in this case), the more serious problem is that attendance appears
to be the recipient of some unspecified direct object.
4.Morphologic
Ambiguity in the Source Text.There
are many instances in human language where the surface form of a word and
its context are not sufficient to derive the information normally imparted
by morphology.For instance, in the
German ?die in den vergangene fünf Jahren Darlehen für mehr als
1 Milliarde Dollar (durchschnittlich weniger als 500 Dollar) an Klenstunternehmen
vergeben haben?, Darlehen, loan, is ambiguous with respect to number.GTS
produced ?which have distributed in the past five years loan for more than
1 billion dollar,?incorrectly guessing
singular.As humans with world knowledge,
we understand that banks make more than one loan every five years, and
the parenthetical comment about the average loan amount reinforces this.Assuming
an analysis component which is powerful enough to figure out cases like
this, an IL-based approach will address this type of error, since the IL
representation will contain information about number, gender, thematic
role, etc.
5.Sentence-Level
Phenomena.In this category we consider
such phenomena as tense, mood, and aspect.These
phenomena associated with verbs express important semantic content.As
before, we assume that substantial problems of analysis can be solved,
and that IL representations contain representations of the semantic content
encoded by tense, mood and aspect.Consider
this example, from the Spanish version:
Spanish:La
transición? iba a durar dos años?
GTS:The
transition? was going to last two years?
Systran:The
transition? were going to last two years?
Human:The
transition required two years? work?
An
IL representation of the original Spanish would represent the transition
as something which happened and did last two years.This
would avoid the unclear English translations, in which it is not clear
whether the transition lasted two years, or was ever accomplished.
6.Compositional
Phrasal Units.Non-composition phrases
must appear in a lexicon in order to be successfully translated, because
of their characteristic that their meaning cannot be derived from their
components, e.g. ?kick the bucket.?However,
many compositional phrases should be quite intelligible.Consider
the Spanish:
Spanish:préstamos
de una cuantía media inferior a qunientos dólares.
GTS:loans
of an inferior mean quantity to five hundred dollars.
Human:loans
averaging less than five hundred dollars.
In
an IL representation, this property should appear as a modifier to loans.In
the generation phase, it will be realized using the appropriate lexical
elements from the target language.
Lexical
Mismatch.As in the example of Spanish
pescado
(fish as a food) versus pez (fish as an animal) given in Dorr(1993),
it is common for a word in a source language to contain more or less information
than its counterpart in a target language.In
English, there are three lexical items who, that and which,
that correspond to French qui.Without
information concerning the referent (human or not) and the context (restrictive
or not), transfer-based MT systems regularly make errors in choosing the
correct English word.
7.Lexical
Incorporation / Conflation.Conflation
refers to the inclusion of an argument within a word?s meaning.As
an example, the English verb telephone can be thought of as call
using a telephone, and llamar por teléfono is a good Spanish translation
of this verb.Although we did not
find errors of this type in the sample data, we include it here as a situation
in which an IL-based approach will be particularly helpful.
Lack of Resources
We identify ten categories
of errors that we do not believe will be solved by IL-based MT systems,
because the error arises from a general lack of resources.The
factor which disrupts successful translation occurs before transfer rules
are applied, or before the IL representation would be generated.We
do not regard these errors as inherent to transfer based systems.
1.Errors
in source data.Some words are not
recognized because of errors in the source data.The
Spanish text contained hyphenated words in the middle of a line of running
text (e.g. infe - rior for inferior), presumably an artifact
of the conversion of the document from a previous format.The
missing resource in this case is appropriate pre-processing tools to recognize
and correct such errors.Other types
of errors which are best addressed by pre-processing include spelling correction,
diacritic reinsertion, and encoding recognition.These
and other pre-processing tasks are among the primary services provided
by CyberTrans.
2.Gaps
in the lexicon.Lexicon acquisition
is a problem for all types of MT systems.For
example, neither MT system knew the German verb unterstüzt.
3.Failure
in morphological analysis.MT systems
commonly try to perform morphological analysis on unknown words, or break
a word into smaller chunks in order to match them with known lexical entries.Neither
system was able to analyze the unusual German Kleinstunternehmer
as klein small + st ? + unternehmer businessman. In
contrast, French micro-enterprise was inappropriately separated
into micro + enterprise microphone company.
4.Parsing
errors.Robust parsers are another
scarce resource.Consider the following
example
Spanish:En
cinco años BancoSol se ha convertido?
GTS:In
five years Bancosol itself has converted?
Systran:Into
five BancoSol years one has become?
Human:In
five years, BancoSol has become?
We
assume that Systran analyzed BancoSol as a modifier of años and
finding no subject for the reflexive verb provided inserted the generic
pronoun one.
5.Named
entities.The author?s name was not
often recognized as an element not to be translated.It
was rendered variously as ?Marrying Otero,? ?Maria Hill? and ?Maria Knoll?.We
have observed similar problems occurring with e-mail addresses.Comprehensive
gazeteers are also scarce resources.
6.Non-compositional
Phrasal Units.This is similar to
class #2 in that it is a problem that points to gaps in the MT systems?
lexicons.For instance, Systran
translated the French phrase à but non-lucratif as ?with
nonlucrative goal?, rather than as ?non-profit?.IL
representations will not improve this situation unless they include a substantial
amount of real-world knowledge.In
this case, for a system to generate ?non-profit? from the IL, it would
need to know that ?non-profit? describes an entity?s goals, rather than,
e.g., its size, location or properties when submerged in water.However,
another writer might have rendered the concept ?non-profit? as ?with nonlucrative
methodology? or ?with nonlucrative status.?A
robust representation of what it means for an entity to be ?non-profit?
seems well beyond the scope of existing interlingual representations.
AI-Complete Systems
Are Not Yet Available.
The last class contrasts
a resource problem (gaps in the lexicon) with tasks that we do not expect
MT systems to perform (figuring out the meaning non-compositional phrases
on the fly).The following error
classes are also not expected to benefit from IL-based MT, because they
exist well beyond the current state of the state-of-the-art for human language
processing.
1.Target
word sense override.This is a rather
subtle case in which an appropriate target language word is chosen to express
some element of the internal representation, however in the final surface
form, some other sense of the target word seems to override the intended
sense.Consider:
German:die
Institutionen? technisch unterstütz
GTS:
[the] institution? technically supports
Human:the
institution? provides technical support.
In
this case, technically in the sense of ?having specialized knowledge
of a scientific topic? is certainly the correct target word, however it
seems to be overshadowed by the sense of ?being marked by a strict or legalistic
interpretation.?
2.Implications
or Entailments.A translation may
bear implications or entailments not borne by the original.Consider
Spanish:que
brinda actualmente?
GTS:that
offers currently?
Systran:that
at the moment offers?
The
second translation implies that the offer will eventually be rescinded,
while the first translation and the original do not make this implication.
3.Discourse-level
Phenomena.Although we have not (yet)
encountered any discourse-level translation problems in the text in question,
this class is a natural progression from the sentence-level phenomena.Given
a large enough body of text, discourse-level phenomena would certainly
present themselves.For a discussion
of IL treatment of discourse-level phenomena, see (LuperFoy & Miller,
1997)
4.Humor.The
titles of both the English and Russian articles make puns on the entity
name ACCION International, while the French, Spanish and German titles
do not.Fortunately, automatic generation
of cute journalistic headline puns is not currently a major goal of the
MT research community.
An Interlingua:
Lexical Conceptual Structures
We
will represent some sentences from the source text in the style of lexical
conceptual structures (LCS).A sentence
is represented by a composed LCS (CLCS) and a lexical entry is represented
by a root LCS (RLCS).At present,
verbs, prepositions and nouns which denote events or states are assigned
lexical entries;nouns which do not
represent events or states are treated as atomic entities.
 The
core insight which allows CLCSs to represent a wide range of sentences
is that the semantics of motion and location serve as an analogy for many
other areas of human understanding [Gruber 1965].For
instance, by regarding time as a one dimensional space, events can be positioned
in time (sentence 1), just as things or events are positioned in space
(sentence 2).
The
core insight which allows CLCSs to represent a wide range of sentences
is that the semantics of motion and location serve as an analogy for many
other areas of human understanding [Gruber 1965].For
instance, by regarding time as a one dimensional space, events can be positioned
in time (sentence 1), just as things or events are positioned in space
(sentence 2).
(1) The
meeting is at 3:30
(2) The
meeting is in Dr. Dorr?s office.
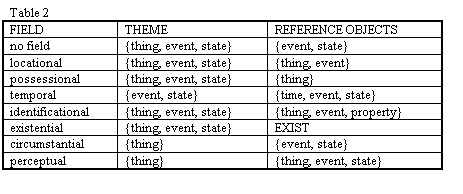
The
distinction here is among semantic fields, temporal and locational respectively.A
semantic field can be described as an analogy between physical motion and
a motion analog and between physical position and a position analog.Semantic
fields can be described by three parameters[Jackendoff 83]:
(1) what
type of entities can assume the role of theme, i.e., undergo the motion
analog or be located by the position analog,
(2) what
type of entities can serve as reference objects to define the path of the
motion analog or location of the position analog
(3) what
concept is represented by analogy to motion and location.
In
order to understand the different semantic fields, we must first know what
values can fill in the parameters described above.The
types of entities, or semantic types, which will serve to restrict themes
and reference objects with respect to fields are as follows.Things
include all physical objects (e.g. table, telephone, James Garfield) as
well as non-physical human concepts (e.g. idea, hope, intelligence, Calculus,
?Romeo and Juliet?) and human conceptual organizations applied to physical
objects (e.g. the faculty of the Computer Science department, MITRE Corporation).States
are sets of conditions which apply to some universe over time.Events
are changes in those conditions:in
an event, something happens.Times
are points or intervals along the one-dimensional timeline.Properties
are characteristics which can apply to things.
In
[Dorr 93] nine semantic fields are identified:locational,
possessional, identificational, perceptual, existential, circumstantial,
intentional, instrumental and temporal.In
addition, some causative events may exist without any state.Instrumental
and intentional fields do not apply to events and states, but are used
in adding additional information about an event or state to a CLCS.Table
1 shows the restrictions on semantic types as they serve as parameters
of themes.
For
the locational field, the relevant issues are where a thing is located,
where an event takes place, and where a state holds.If
a reference object is a thing, the location of the theme is given relative
to the location of the reference object.If
the reference object is an event, the location of the theme is given relative
to where the event takes place.In
the possessional field, the theme is possessed by the reference object.More
recent work has downplayed the use of the temporal field in favor of representing
temporal information in modifiers.Themes
of the identificational field are instances of or identical to a reference
object, or bear a property.In the
existential field, the theme is understood to exist for things, to have
happened for events, or to hold true for states.In
the circumstantial field, the theme is a character in a reference situation
(event or state), as in ?Ludwig continues to compose string quartets? or
?Xavier avoids being rude.?Lastly,
the theme of the perceptual field perceives a reference thing or situation.
A
place is a prepositional relation to one or more reference objects.The
reference object can be any of the semantic types, and the prepositional
relation describes the position of a theme with respect to the reference
object(s) (e.g., above, at between).A
prepositional relation may make use of zero or more reference objects,
as in
?here?
?above
the printer?
?between
World War I and World War II?
A
path is a path operation applied to one or more places.
We
will not attempt to enumerate the primitives of the LCS system here, however
we will make use of representative primitives in our examples.
CLCSs
take the form of trees with each node of the tree an instance of a common
node structure.In our examples we
will make use of an informal adaptation of the LCS short-form notation.Moreover,
the process of encoding sentences as CLCSs is, at present, something of
a craft, and quite a non-trivial craft for complex sentences, such as those
found in the article by Otero.
Applying
the Craft:Mapping Text into Composed
Lexical Conceptual Structures
We
will present an example CLCS representation of a fragment from the Spanish
text that was translated incorrectly by the transfer-based MT systems.We
will show how the representation is created and suggest that better results
can be obtained using the IL representation.
Consider the note about the author: ?María Otero, estadounidense de origen boliviano, es vicepresidenta de la asociación Acción Internacional.?This is translated by GTS as ?Maria Hill, American of Bolivian origin, it is vice president of the association International Action.?Our focus will be on the incorrect addition of the default subject it in the English translation.This is an error of class Generation Problems Attributable to Transfer Rules:it seems that the appositive prevents the system from recognizing Maria Otero as the subject of ser.
The first step is to find the LCS definition of
the verb ser.It is given here in
a simplified form.The first element
is the type of the node, the second is an entity type.Then
follows either a primitive and a field, or an indication of the theta role
of the variable to be filled in when the definition is composed to represent
actual text.Theta roles are shown
in italics.
(ROOT: STATE BE IDENTIFICATIONAL(SUBJECT: THING THEME)(ARGUMENT: POSITION AT IDENTIFICATIONAL
(SUBJECT: THING THEME)(ARGUMENT: THING/PROPERTY IDENTIFICATIONAL PREDICATE)))Not shown here are the variable specifications that put constraints, such as +HUMAN, on the entities which may fill a variable.
(ROOT: STATE BE IDENTIFICATIONAL(SUBJECT:?Maria Otero?)(ARGUMENT: POSITION AT IDENTIFICATIONAL
(SUBJECT: ?Maria Otero?)(ARGUMENT: ?vicepresidenta?
(MODIFIER: ?de la asociación Acción Internacional?)))(MODIFIER: ?estadounidense de origen boliviano?))
Finally we will realize the CLCS in English.A verb is sought whose definition is compatible with the structure of the CLCS.In this case be is the unsurprising candidate.Its LCS definition is identical to that of ser.A generation system based on this CLCS might produce the English surface forms: ?Maria Otero, a Bolivian-born American, is the vice president of Acción Internacional.?
Future Work
Regarding automatic generation of CLCSs from parsed text, much work remains to be done.In particular, the needs to be a more specific representation of the relationship between modifiers and the entities they modify.
Regarding our analysis of errors in existing MT systems, a larger corpus of text should be analyzed, and the resulting data should be used to generate frequency statistics organized by MT system and by language pair.It may be shown that certain types of errors are typical of a particular system, and not characteristic of transfer-based MT in general.We might also discover that certain language pairs cause certain types of errors across MT systems.
References
Jackendoff, Ray S. Semantics and Cognition.MIT Press, Cambridge, MA, 1983
LuperFoy, Susann and Keith Miller, The Use of Pegs Computational Discourse Framework as an Interlingua Representation, AMTA SIG-IL First Workshop on Interlinguas (held at MT Summit VI), San Diego, California, 1997.
Miller, Keith and David Zajic, Lexicons as Gold: Mining, Embellishment, and Reuse, AMTA-98 (to appear).
Otero, María, ?Latin
America: ACCION Speaks Louder Than Words?, UNESCO Courier, January,
1977.
Pustejovsky, James, ?The Generative Lexicon?, Massachusetts Institute of Technology, 1995
Reeder, Florenceand Dan Loehr, Finding the Right Words, AMTA '98 (to appear).